Haiqu’s data loading methods allow encoding of an arbitrary data into the amplitudes of the quantum state. They are particularly useful for applications in quantum simulation, machine learning, quantum optimization, solving differential equations and others.
Loading an arbitrary 1D data vector
Here we introduce one of the loading procedures available in Haiqu SDK:Vector Loading allows to load a vector (1D array) of classical data directly into the amplitudes of a quantum state, producing compact, linear-in-depth circuits.
The input vector is a real- or complex-valued one-dimensional vector, which contains the values to be encoded in the amplitudes.
Vector Loading automatically adjusts to the closest minimal necessary number of qubits and normalizes the data. The current supported maximum size of the vector is .haiqu.vector_loading(...).
vector_loading , like all other Haiqu’s data loading routines, returns a HaiquCircuitGate object, which is an abstract Qiskit circuit instruction and can be substituted into user’s circuits at any place just like other standard gates. HaiquCircuitGate will be unpacked into elementary gates, performing state preparation, at transpilation time internally.
All data loading jobs report a global quantum state fidelity of the synthesized circuit, that is, an overlap with a quantum state, defined by the input data, and a state, produced by a generated quantum circuit, is computed. It allows to access the quality of the result and possibly tune the synthesis parameters.
Loading an arbitrary state at utility scale
Amplitude encoding has a scaling limitation: it is not possible to explicitly store in a classical memory a state vector for arbitrary large systems, therefore it is not possible to applyVector Loading to them. To alleviate this problem we use the Matrix Produce State (MPS) representation of a wave-function. It is written as a sequence of matrices (tensors) which, when contracted, restore the original state vector. Setting a limit on sizes of such matrices allows to store a “compressed” version of a quantum state at large scales, inaccessible by other means. MPS is a popular method for large scale simulations, however can successfully (without large errors) represent only states with low entanglement.
Haiqu SDK contains the MPS Loading method, which can generate state preparation circuits at utility scale. The method takes a MPS as an input and supports two MPS formats: the standard MPS (written as sequence of site tensors) and the Vidal form (where in addition a sequence of bond tensors appears). Using MPS Loading is very simple:
Loading multidimensional data
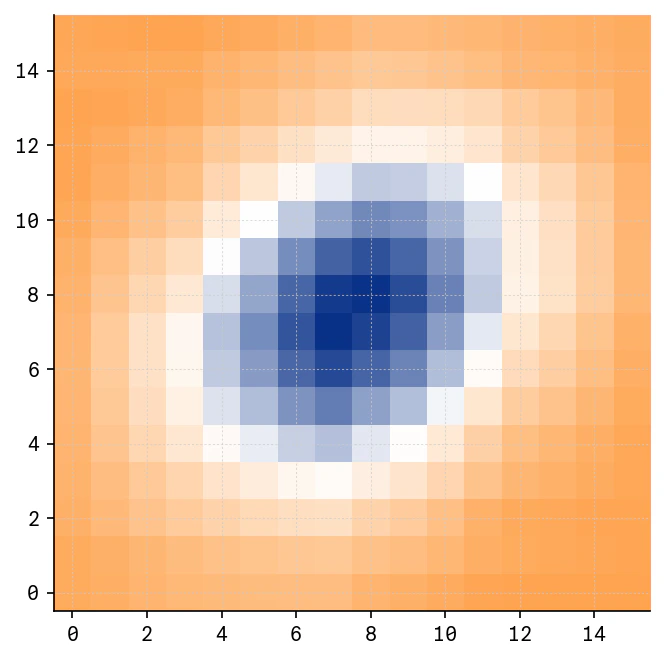
In many applications, the input data is naturally represented as a multidimensional array. In the following example we show how to load a custom 2D distribution. First, we prepare a 2D array with multivariate normal distribution on a rectangular grid:haiqu.vector_loading(...) expects a one-dimensional input vector, the data array should first be flattened:
haiqu.vector_loading(...):