Error suppression & mitigation stack
Benchmark: 2D transverse-field Ising model
We reproduce the experiment from IBM’s Nature publication using Haiqu’s lightweight error mitigation techniques.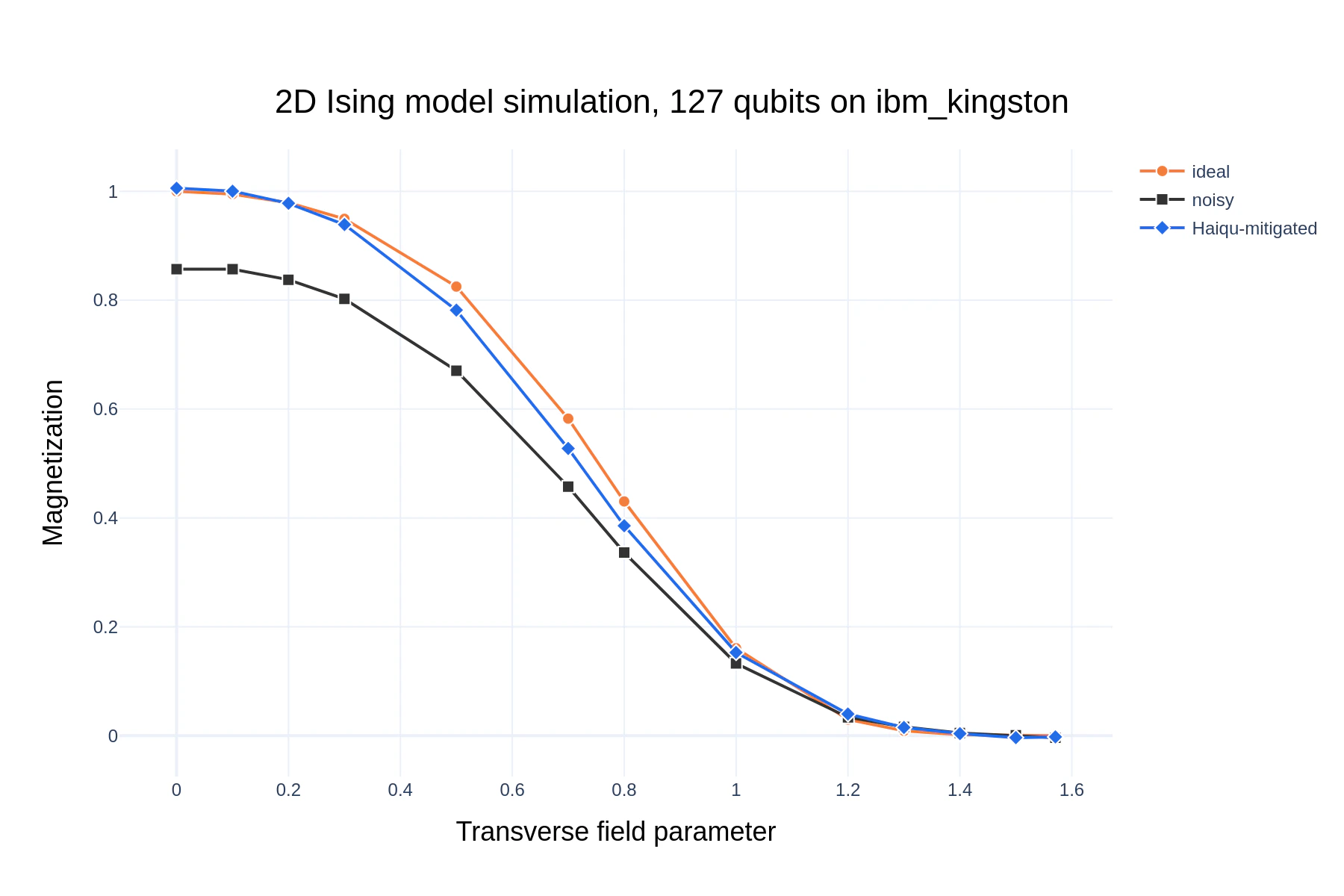
IsingModelSimulation.ipynb notebook.
Benchmark: GHZ state preparation
We prepare GHZ states on IBM Heron r2 processor by hardware-efficient circuits (found by breadth-first search (BFS) algorithm) with Haiqu’s bitstring distribution error mitigation.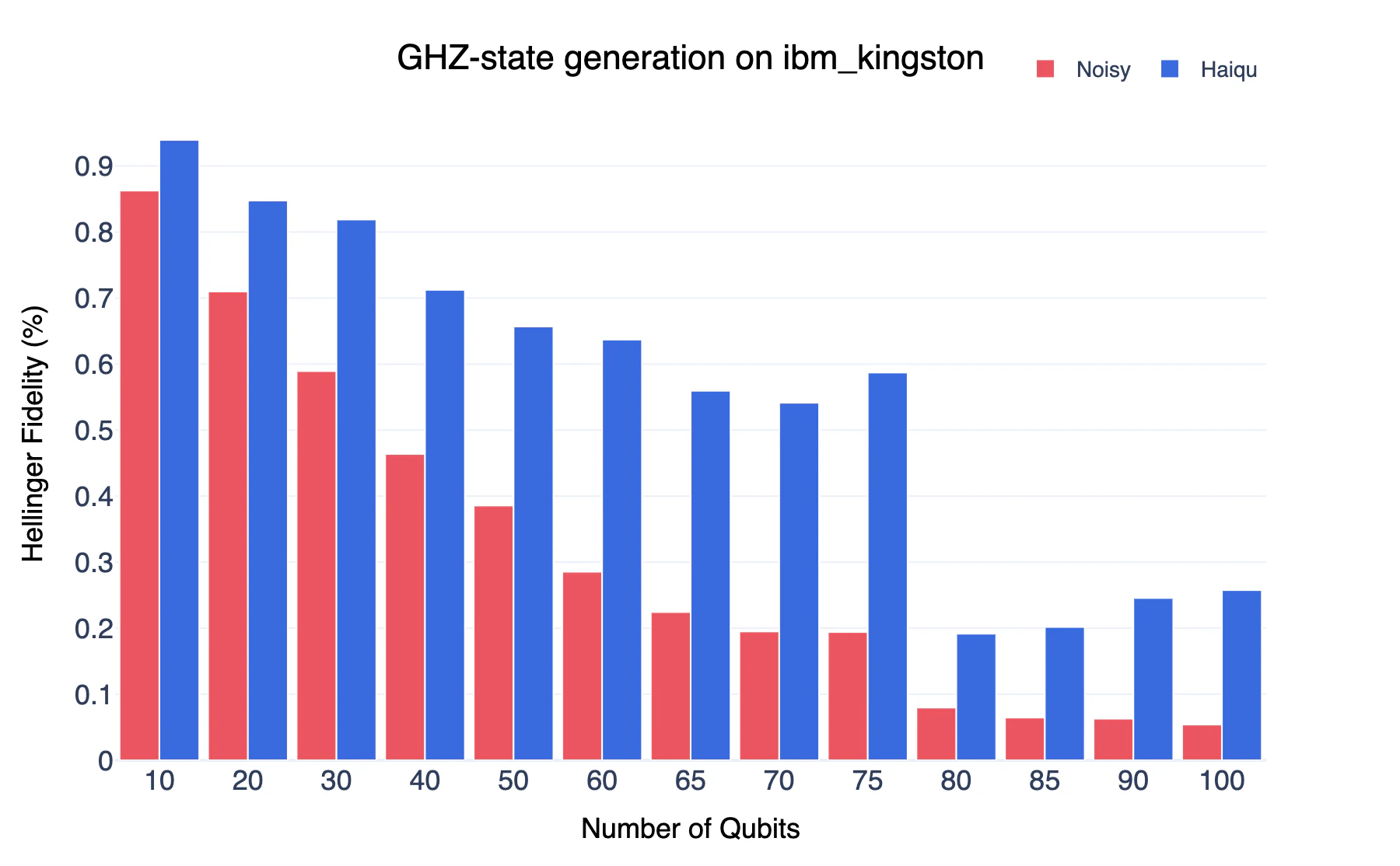
GHZStatePreparation.ipynb notebook.
Mitigation Loading Specifications
| Observable-based mitigation | Bitstring distribution mitigation | |
|---|---|---|
| Supported backends | IBM QPUs, AWS Braket (TBD) | IBM QPUs, AWS Braket (TBD) |
| Max number of qubits | up to 156 qubits (largest QPU) | up to 156 qubits (largest QPU) |
| Max. circuit depth / gate count | up to 1000 2q gates for up to weight-5 observables, up to 300 2q gates for highly non-local observables | up to 300 2q gates |
| Circuit execution overhead | 2x more circuit executions per unique circuit | 2x more circuit executions per unique circuit |
| Shot overhead | 2x more shots per unique circuit | 2x more shots per unique circuit |
| Execution speed | O(1) seconds for QEM + execution time on QPU | O(10) seconds for QEM + execution time on QPU |
State compression
Benchmark: Utility-scale LR-QAOA
Following recent paper by Montanez-Barrera et. al. “Evaluating the performance of quantum processing units at large width and depth”, we use linear ramp quantum approximate optimization algorithm (LR-QAOA), a fixed-parameter, deterministic variant of QAOA, as a benchmarking protocol. Haiqu’s compression enables execution of nearly 20x more layers of LR-QAOA with the increasing approximation ratio.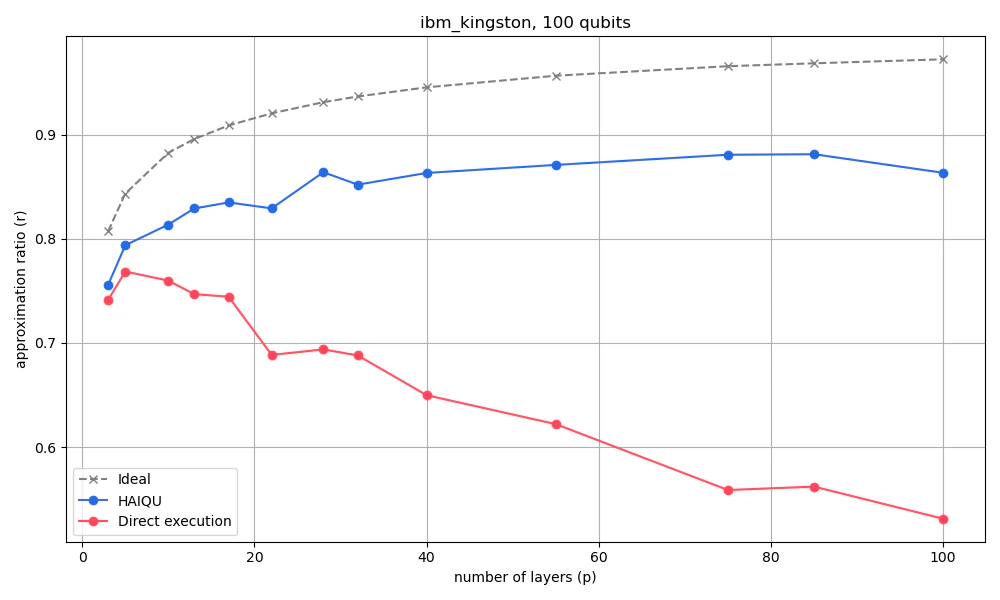
State Compression Specifications
| Parameter | Details |
|---|---|
| Number of qubits | Up to 500 |
| Runtime (at 100 qubits) | From few seconds and up to 2 minutes with no fine-tuning; up to 15 minutes with heavy fine-tuning |
| Runtime scaling | Linear scaling with circuit size, problem-dependent |
| Supported circuits | - Circuits decomposable into CNOT, RX, RY, RZ basis gates - Circuits with mid-circuit measurements are supported, but compression applies only prior to MCM |
| Supported connectivity | Any. Not transpiled input with Linear connectivity is preferred. |
| Compression rate | Up to 100× for various application circuits |
| Returned metrics | - Compression rate - Quality of the compression (fidelity-like metric) |
Data loading
Distribution Loading Specifications
| Parameter | Details |
|---|---|
| Number of qubits | Up to 500 qubits |
| Number of distributions | 107 different classes of distributions are supported. Check SciPy docs for details. |
| Runtime | 1–15 seconds |
| Runtime scaling | Linear scaling with number of qubits |
| Circuit size (gates count) | O(n), n = number of qubits |
| Circuit depth | O(n/2), n = number of qubits |
| Circuit connectivity | Linear |
| Other circuit properties | - No mid-circuit measurements - Only CNOT and single-qubit rotation gates - No ancillary qubits - No post-selection required in state preparation |
| Returned metrics | Quantum state fidelity is returned for the ideal state prepared by the circuit |
Vector Loading specifications
| Parameter | Details |
|---|---|
| Number of qubits | Up to 20 qubits |
| Input data | 1D vector |
| Data type | Real and complex values |
| Data size | Up to ~1M features in the vector |
| Runtime | 0.5–2 minutes |
| Runtime scaling | Linear scaling with number of qubits |
| Circuit size (gates count) | O(n), n = number of qubits |
| Circuit depth | O(n/2), n = number of qubits |
| Circuit connectivity | Linear |
| Other circuit properties | - No mid-circuit measurements - Only CNOT and single-qubit rotation gates - No ancilla qubits - No post-selection required in state preparation |
| Returned metrics | Quantum state fidelity is returned for the ideal state prepared by the circuit |
Block Vector Loading specifications
| Parameter | Details |
|---|---|
| Number of qubits | 1000+ qubits; no more than 20 qubits for a single block |
| Input data | 1D vector 2D matrix |
| Data type | Real and complex values |
| Data size | Any, with no more than ~1M features for a single block |
| Runtime | 0.5–2 minutes per block |
| Runtime scaling | Linear scaling with number of qubits |
| Circuit size (gates count) | O(n), n = number of qubits |
| Circuit depth | O(m/2), m = number of qubits in each block |
| Circuit connectivity | Linear within each block |
| Other circuit properties | - No mid-circuit measurements - Only CNOT and single-qubit rotation gates - No ancilla qubits - No post-selection required in state preparation |
| Returned metrics | Quantum state fidelity is returned for the ideal state prepared by the circuit |